인용수 37밖에 안되긴 하지만.. 내가 원하는 분야와 완전히 일치해서 한번 리뷰해보려 한다.
Abstract
Automatic Emotion Recognition (AER) 분야에서의 주요 challenge는 다음과 같다
너무 많은 감정 표현과 추상적인 개념...
-> 그럼에도 일상에서 사람들은 감정을 구분하기 때문에 충분히 연구할 만한 의미가 있는 분야이다.
우리는 사람의 목소리와 표정을 합친 멀티모달에 기반해서 이 분야를 연구할건데, 대부분의 전통적인 멀티모달 (여기선 video, audio)의 fusion 방법은 linear paradigm(feature concatenation ... )에 기반한다.
이 논문에서 주요 특징/기술은 다음 3가지로 설명할 수 있다.
- Factorized Bilinear Pooling (FBP) -> audio와 video를 더 deeply하게 integrate하기 위함
- embedded attention mechanism으로 선택된 각 모달의 feature
- 전체적인 pipeline이 neural network에서 이뤄짐
Section1: Introduce
사람의 감정을 더 자세하게 분석하기 위한 대회로써 AFEW 데이터베이스의 audio-video clip에 기반한 사람의 감정을 identify하는 EmotiW라는 대회가 있다.
결국에 사람의 얼굴 기반 감성 분석과 오디오 기반 감성 분석으로 이루어지게 되고, 각각의 전통적인 방식은 다음과 같다.
Facial Emotion Recognition (FER)에서 traditional approach
- input image에서 face를 찾고 component(눈, 코, 입 .. )을 확인
- facial component로부터 various한 spatial & temporal feature를 extract
- 해당 feature들을 SVM, random forest 등으로 학습
이 때, handcrafted feature와 차이점이 있다면 CNN을 사용함으로써 raw image로부터 task-dependent feature를 directly하게 학습한다는 것이다.
그리고 CNN을 활용한 SSE, DSN 등... 다양한 방법이 있다고 하는데.. 이건 나중에 보자..
중요한건, video에서 face image sequence를 위해 기존에는 LSTM + 3D CNN이 많이 사용됐다는 것이다.
하지만 LSTM + 3D CNN을 사용하게 되면 모든 video frame에 대한 정보를 사용하게 되는데, 문제는 모든 frame이 emotion information을 갖고 있지 않다는 것이다.
그래서 이 논문에서는 각 프레임에 대한 가중치를 위해, attention mechanism을 사용한다.
Speech Emotion Recognition (SER)에서 traditional approach
FER의 기존 방식과 거의 유사하다.
- left-to-right slide window를 통해 acoustic feature를 추출
- 각각의 sentence에서 various statistcal function(아마 SER논문에서 말하는 HSF(High Statistical Function)인 듯함)에 기반한 global vector feature가 frame-level feature와 combine하면서 얻어진다.
- utterance vector를 classifier에 넘겨줌
여기서도 기존에는 LSTM + CNN이 많이 사용됐지만,
이 논문에서는 fully convolutional network에 기반한 novel attention을 소개한다.
MultiModal Fusion
두 가지 결과에 대해 fusion하는 기존 방식을 decision-level fusion이라고 하는데,
decision-level fusion은 하나의 모달이 다른 하나의 모달보다 _limited improvement_할 때, 각각의 modalities에 대한 interaction과 correlataion을 무시한다.
그래서 기존에도 이를 보완하기 위해 middle layer에서 linear fusion (concatenation 혹은 element-wise addition)을 통해 단점을 보완하려 했다.
하지만 각 모달들이 갖는 feature의 분포가 너무나도 다르기 때문에 linear한 방법으로는 굉장히 복잡한 관계를 모두 capture하기엔 부족했다.
그래서 이 논문에서는, Bilinear Pooling 방법을 활용할 것이다.
Bilinear Pooling은 일반 linear model과 다르게, fine grained image recogition을 통해 서로 다른 CNN feature들을 통합하는데 유용하다.
fine grained image recognition이란 아주 세세한 이미지의 차이를 더 잘 찾아내는 것을 의미한다.
(이건 나중에 좀 더 자세하게 알아보자)
Visual Question Answering (VQA)에서 multi-modal factorized bilinear pooling에 영감받아,
이 논문에서는 최종적으로 Factorized Bilinear Pooling (FBP)를 제안한다.
-> bilinear pooling의 개선된 버전으로써 audio & video feature를 합치는데 있어 computational complexity를 줄여준다.
Section2: The Proposed Architecture

최종적인 모델의 아키텍쳐는 위와 같다.
이 논문에서 audio emotion recognition을 위해 Fully Convolutional Neural Network를 통한 novel attention을 제안한다.
이 논문에서 제안하는 attention mechanism은 speech spectrogram에서 모델이 emotion-relevant region에 집중하는걸 도와주는데, 이건 뒤의 video에서도 emotion-relevant frame을 찾는데에서도 동일하게 쓰인다.
그렇게 각각 병렬적으로 audio, video로부터 emotion-relvant feature를 뽑아내고, 분리된 특별한 특징들(?) (논문에서 separate salient features라고 불리는데.. 특별한건진 그냥 각자의 특징인건지 자세하게는 모르겠다..)을 최종 예측을 위한 각각의 모달리티간의 관계성을 deep 하게 capture하기 위해 FBP block에서 합친다.
이제 하나씩 보자
Audio Stream
Fig 1을 보면 attention block으로 이루어진 convolutional layer를 stack 하면서 speech spectrogram을 직접적으로 다룬다.
CNN은 speech emotion recognition(SER)에서 이미 많이 사용되고, 기본적인 component로 convolution, pooling, activation layer로 구성된다.
convolution layer에서 parameter는 [ input channels, output channels, kernel size, stride]가 있고 각각의 kernel은 input feature map보다 작은 size의 filter가 된다.
feature map에서 kernel의 parameter는 공유되는데, 이는 network의 복잡도를 줄이고, 다른 location에 있는 특정한 pattern을 찾는다고 한다. (뭔소린지 모르겠음...)
pooling layer는 일반적인 것과 마찬가지로 average, max pooling을 사용하고, activation layer에는 element-wise nonlinear function을 사용한다는데.. 이게 뭔지도 나중에 좀 더 알아보자..
중요한 건 지금부터!
기존의 CNN (AlexNet, VGGNet, ResNet)에서는 fully-connected layer의 제한 때문에 고정된 사이즈의 input을 사용했었다.
이 논문에서는 variable length speech를 다루기 위한 fully convolutional network를 사용한다.
(fully convolutional network가 variable length speech를 다루는데 왜 용이하지? 나중에 찾아보자..)
audio encoder의 output을 assuming하면 F * T * C의 3차원 array가 나온다.
- F: Frequency of spectrogram
- T: Time domain of spectrogram
- C: number of Channels
L = F*T
output = L element의 가변길이의 grid
각각의 element(ai)들은 speech spectrogram에 위치하는 C-dimensional vector이다.
(그래서 최종적으로 output = F*T*C의 3차원 array가 나오게 되는 것)
utterance (whole audio)는 다음과 같이 표현된다.
A={a1,...,aL},ai∈RC
이때, all time-frequency가 전체 utterance의 감정 상태에 동일하게 영향을 끼치지 않는다.
그래서 attention mechanism을 활용해 utterance의 주요 감정 요소를 extract하고,
attention mechanism을 통해 나온 감정 요소들에 대해 weighted elements의 합은 audio-based emotional feature를 나타낸다.
Attention Block은 다음과 같이 표현할 수 있다.
ei=uTtanh(Wai+b)(1)αi=exp(λei)∑Li=1αiai(2)a=L∑i=1αiai(3)
하나씩 자세히 보자.
step1
ai는 ai에 대한 새로운 표현을 얻기 위해 tanh를 따른 fully connected layer에 주어지게 된다.
(왜 새로운 표현을 얻는데 tanh가 필요한지는 나중에 자세히 알아보는 걸로...)
step2
tanh를 통해 나온 새로운 표현인 ai와 learnable vector u의 내적을 통해 중요 가중치(importance weight) ei를 계산하게 된다.
step3
importance weight ei를 Softmax 함수로 normalization해준 αi를 얻는다.
Softmax Normalization이유: 스케일의 차이를 더 크게 내기 때문

(참고로 exp(1)=e1)
step4
마지막으로, vectora는 가중합(weighted sum of elements in set A with importance weights)으로 계산되고, 이는 최종적으로 audio-based emotional feature가 된다.
(3)식에서 λ는 0~1 사이의 수로써 importance weights의 uniformity를 조절하는 scale factor이다.
uniformity: 균일도 - 얼마나 균일하게 분배됐는가에 사용
if λ=1, the scaled-softmax becomes the commonly used softmax function
if λ=0, the vector a will be an average vector of the set A, which means all the time-frequency units have the same importance wieghts to the final uttenrance audio vector
즉 lambda가 1일 경우에는 일반적으로 사용하는 softmax function에 따르게 되고
lambda가 0 일 경우 A(오디오 벡터)의 평규이 되는데, 이는 최종 utterance vector의 중요 가중치가 all time-frequenecy에서 동일한 것을 의미한다.
Video Stream
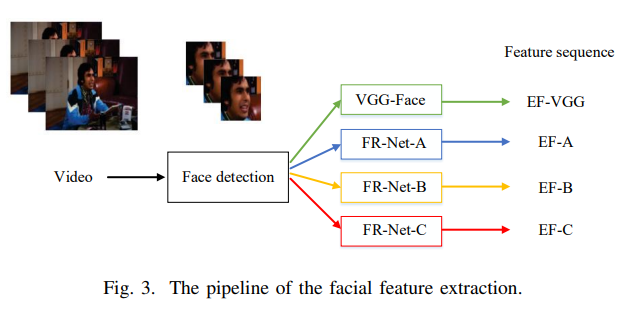
emotion recognition을 위해 4가지의 facial feature가 proposed 되고 이후의 진행은 audio stream과 거의 유사하게 진행된다.
기본적으로 이전의 facial feature extraction에 대한 연구들이 있어서 이를 기반으로 진행된다.
Pipeline for Extract Emotion Recognition Feature
step1
Face Detection: dlib face detector는 FER2013 database와 EmotiW video frames에서 얼굴 이미지들을 추출하고 맞추는데 사용된다
step2
FER2013- fine-tuning: 얼굴 이미지에서 감정과 관련한 feature를 추출하기 위해 4개의 deep convolutional neural network를 사용한다. (VGG-Face와 당시 face recognition network의 SOTA였던 3개의 모델 FR-Net-A, FR-Net-B, FR-Net-C) 모든 모델들은 FER2013 database에서 감정과 관련하여 fine tuning된다.
step3
Emotional feature extraction: 모든 프레임에서 feature들은 4가지 네트워크를 모두 사용하여 계산되는데,
VGG-Face에서는 fc6 layer에서 생성된 4096 차원의 feature를 선택하고, 다른 네트워크에서는 last layer의 output이 사용된다.
이 논문에서는 이를 EF-VGG, EF-A, EF-B, EF-C라고 말하며, L-Frames에 대한 visual feature sequence는 다음과 같이 표현한다.
V={v1,…,vL},vi∈RC
vi is facial feature of frame i, and C is the feature dimension
이후의 과정은 audio stream과 거의 동일한데 주의해야할 것이 하나 있다.
attention block에 들어가기 전에 computational complexity를 줄이고 over-fitting을 막기 위해 차원을 줄이고 넣어야 한다는 것이다. (밑의 (6)번이 차원을 줄이는 것 같은데... 잘 모르겠다..)
˜vi=Wvi+b(6)˜e=˜uTtanh(˜vi)(7)˜αi=exp(λ˜ei)∑Lk=1exp(λ˜ek)(8)˜v=L∑i=1˜αi˜vi(9)
˜vi: new low-dimension representation of frame i
˜v: video-based emotional feature
Audio-video Factorized Bilinear Pooling
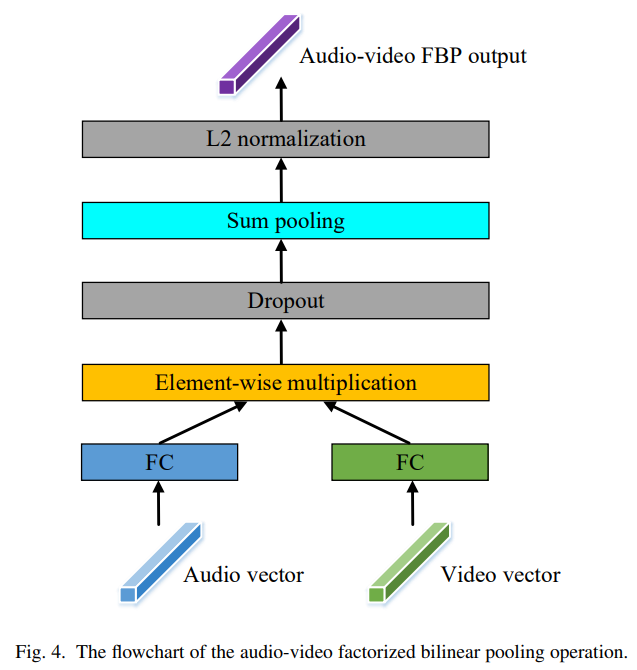
이제 각각의 모달에서 받은 vector를 합치는 방법을 소개한다.
여기서 중요한 것은 두가지를 잘 표현하며 합치기 위해 어떻게 고민했는가? 를 잘 생각하며 보자.
먼저 각각의 modal에서 a∈Rm,v∈Rn feature vector를 받는다.
이때 가장 간단하게 multi modal bilinear pooling을 하게되면 수식은
zi=aTWiv가 된다.
Wi∈Rm∗n = Projection Matrix
zi∈R = output of bilinear pooling
O−dimensional output z=[z1,...,zo]를 얻기 위해서는 W=[W1,...,Wo]∈Rm∗n∗o가 학습되어야 한다.
그런데, bilinear pooling이 두 모달간의 interaction을 잘 잡긴 하지만 parameter가 너무 많아서 계산 cost 효율이 별로 좋지 못하다. 그래서 latent factor에 유용한 Matrix Factorization에서 영감을 받아 projectiom Matrix Wi는 두 low rank matrices에 factorized 될 수 있다.
factorized 된다는 건 truncated SVD를 통해 고유값을 기반으로 A′을 만들수 있다는 것을 의미하는 것 같다.
(고유벡터 및 SVD는 여기서 -> https://velog.io/@jsyeon/%EA%B3%A0%EC%9C%A0%EA%B0%92 )
수식은 다음과 같다.
zi=aTUiVTiv=k∑d=1aTudvTdv=1T(UTia∘VTiv)(11)
k는 factorizing matrices인 Ui=[u1,...,uk]∈Rm∗k 와 Vi=[v1,...,vk]∈Rn∗k가 (∘)element-wise multiplication한 latent dimension이고, 모든 1∈Rk는 모두 1인 vector이다.
output feature vector인 z를 얻기 위해서는 또 U=[U1,...,Uo]∈Rm∗k∗o와 V=[V1,...,Vo]∈Rn∗k∗o가 학습되어야 한다. U와 V는 다시 2-D matrices로 형태로 표현되어 ˜U∈Rm∗ko와 ˜V∈Rn∗ko로 reshape할 수 있다.
따라서 최종적으로
z=SumPooling(˜UTa∘˜VTv,k)(12)라는 수식을 얻을 수 있다.
여기서 ˜U와 a의 내적, ˜V와 v의 내적인 ˜UTa,˜VTv는 a와 v를 fully connected layer에 feeding함으로써 상대적으로 biases없이 얻을 수 있다.
SumPooling(x,k)는 non-overlapped windows to x한 series내에서 sum pooling 함수를 적용한다는데, 그냥 stride를 통해서 서로 겹치지 공간 없이 sum pooling을 진행했다고 생각하면 될것 같다. (왜 sum pooling인지는 잘 모르겠음)
최종적으로 얻은 12번 식을 Factorized bilinear pooling (FBP) 식이 된다.
audio-video의 FBP block의 procedure는 fig4와 같다.
Section3: Experiments
실험의 결과는 다음 그림과 같다.
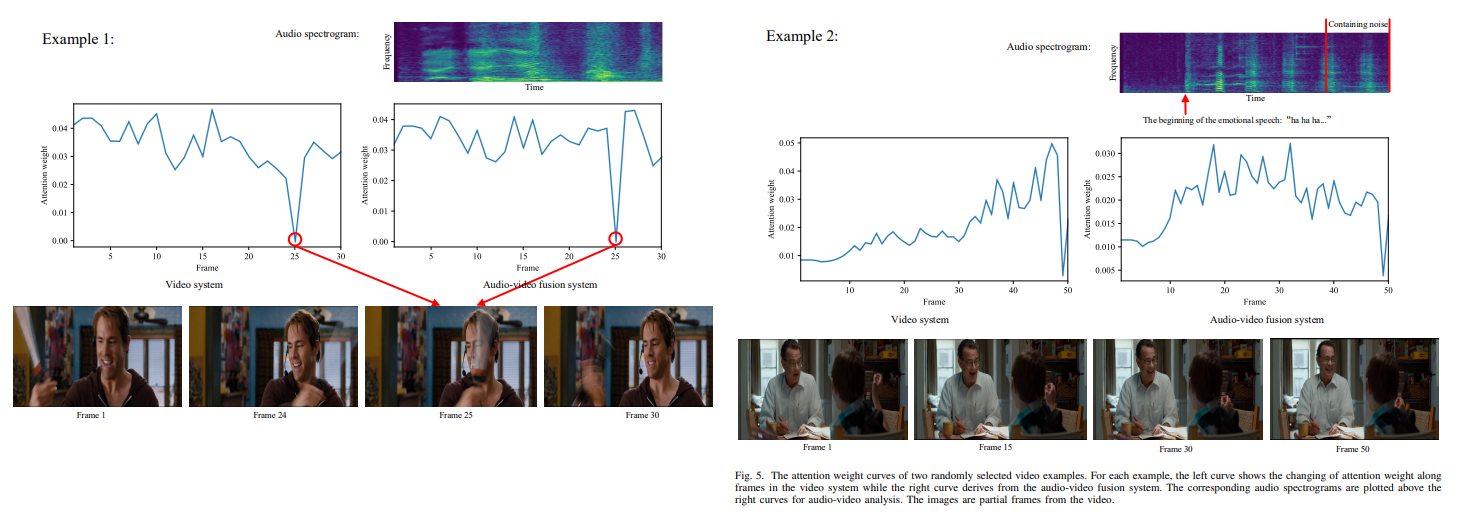
그냥 뭐.. 흔한 논문들처럼 해당 프레임을 포함한 주변 프레임들에서 기존의 단일 성능보다 좋았다는 얘기

