stanford CS231N에서 진행한 Audio + Video의 멀티모달을 기반으로한 감정 분석이다.
Audio를 중점으로 다루기 때문에 오디오 공부에 도움이 많이 되는 논문이다.
Audio에서 뽑아낸 feature를 Video와 결합하는 방식에 있어 [ 오디오와 비디오의 매칭이 맞을 경우, 맞지 않을 경우] 에 대한 Contrastive 학습이 주요 기술로 진행한다.
0. Abstract
audio spectrogram을 처리하는( CNN + RNN ) + 3DCNN을 통한 multi-modal architecture를 video frame에 일치하게끔 하는 것을 제안한다.
이때 video frame은 IEMOCAP Dataset에 기반하고 accuracy가 약 54.0%의 4개 감정과 71.75%의 3개의 감정에 대한 데이터셋이다.
1. Introduction
이 논문은 DNN을 사용해 audio and audios+videos에 기반해 감정 분석을 더 정확하게 하고자 하는 것이 목적이다.
필자는 이미 존재하는 아키텍쳐와 input data에서 bottlenecks에 대해 이해하려 했고, 새로운 감정 분석 방법에 대해 연구했다.
본 논문에서 사용한 IEMOCAP datasets는 10명의 사람들이 (남자5, 여자5) 12시간의 audio visual data를 가지고 anger, happiness, excitement, sadness, frustration, fear, surprise, other, and neutral state에 대한 내용이 포함되어 있다.
본 논문은 2-stage의 방법을 제안하는데,
- 데이터를 복제하고, 확장하면서 audio에서 emotion을 인지할 수 있는 NN를 구축
Input: 배우가 말한 하나의 문장을 변형시킨 audio spectrograms
Output: 배우가 말한 문장에 대한 one emotion
->이 모델은 4가지의 다른 감정(happiness, anger, sadness, neutral)을 예측한다.
Model: CNN, CNN + RNN, CNN + LSTM ) - Audio spectrogram과 video frame을 사용한 예측 모델 구축
Inputs: aduio spectrogram & video frames (하나의 문장을 말한 배우의 video recording의 sound & image를 변형하고 extracted)
Output: 위에서 말한 4개의 emotion중의 하나
Model: 2 sub-network
2-1. video frame을 갖는 3D CNN
2-2. audio spectrogram을 갖는 CNN + RNN
두 sub-network의 마지막 layer를 fully connected layer를 통해 concat해서 최종 output을 도출 해냄
Metric: overall accuracy for both the audio and audio + video models.
2. Related Work
emotion recognition와 관련하여 Speech signals, facial expression, physiological changes를 사용한 선행 연구들이 있다.
해당 연구들을 통해 DNN의 다른 레이어들에서 low-level features (frequency & signal power intensity)에 대한 statistical learning과 함께 recognition accuracy가 오르기도 하며 speech recogntion에서 Mel spectrogram이 유용하다는 것을 증명했다.
Audio spectrogram은 audio signal에 대한 이미지이며, 주요 components는 다음과 같다.
- x-axis: Time
- y-axis: Frequency
- colorbar scale: power intensity (dB)

[12] 논문에서는 audio signal에서 temporal features를 뽑는 ML 방법을 소개한다.
ML의 장점은 training & prediction latency(지연 시간)은 좋지만 accuracy가 낮다는 것이다.
우리가 사용하는 CNN 모델은 감정을 찾는데 있어 audio spetrogram을 사용할 때 ML model보다는 더 좋은 성능을 보여준다.
training할 때 audio spectrograms을 사용하는 [13], [14]에서의 CNN network를 비교하면
[13]은 더 넓은 kernel window size를 사용하며 zero padding을 취한다.
반면 [14]는 더 좁은 window size를 사용하고 zero padding을 하지 않는다.
wide kernel size를 사용할 경우 input에 대한 더 많은 관점을 볼 수 있고 더 powerful할 수 있다. 또한 features의 손실을 막기 위해 zero padding을 하는 것은 굉장히 중요하다. [13] 아키텍쳐에서는 CNN layer가 많아질수록 zero padding은 줄어든다
[14]에서는 extra virtual zero-energy coefficients(local feature를 뽑는데 불필요한)를 consume하지 않기 위해 zero padding이 추가되는 것을 막는다.
[14]에서 우리가 볼 것은 audio model & audio + video model간의 performance를 비교하지 않는다는 것이다.
[14]에서 볼 수 있는 좋은 점은 audio input data로부터 들어오는 noise removal을 하지 않는 반면에 [13]에서는 모델을 훈련하기 전에 audio spectrogram에 대한 noise removal techniques를 사용한다는 것이다.
[11] & [6]에서 audio는 사용하지 않고 image와 video를 사용한 facial emotion recognition을 진행했다.
[14] & [8]에서는 audio spectrogram & video frame을 모두 사용하는 neural network architecture를 구현한다.
[14] & [8] 모두 다른 데이터 셋에서 audio & video 모델을 학습하는 cooperative한 self-supervised model을 구현한다.
[8]은 분류를 위한 pre-trained model에 supervised learning을 한다.
[14] & [8]의 모델은 2-stream model로 (audio part + video part) 거의 유사하다.
차이점: Hyper parameter ( kernel size, layer number, input data dimension의 set )
이유: 하이퍼 파라미터가 다른 이유는 input data가 다르기 때문이다.
[14]: input image: only capture mouth
-> input size와 kernel size를 작게 사용
[8]: 전체적인 사람의 행동을 capture한 이미지
-> 더 많은 정보를 포함
3. Dataset & Features
본 논문에서 Datasets은 IEMOCAP을 사용한다.
IEMOCAP은 몇몇 sentiment가 labeling 된 두 사람간의 대화에서 12시간의 오디오와 비주얼 데이터를 가지고 있는 데이터이다.
3.2 Data pre-processing
3.2.1 Audio Data Pre-processing
IEMOCAP 데이터는 time segment에 일치하는 emotion label이 marking되어있는 audio wav files을 가지고 있다.
sample rate: 22KHz
spectrogram: extracted from librosa with a sampple rate 44KHz
-> 44KHz인 이유는 사람이 들을 수 있는 가청 주파수의 범위는 22Hz~22KHz정도이지만 이를 커버하기 위해선 보통 2배의 sampling rate를 사용하기 때문에 일반적으로 44KHz를 뽑는다.
spectrogram은 2segments로 생성되는데
- Original time length of utterance of sentence or emotion
- Clip each utterance of sentence into 3 second clips
이미 처리된 다른 data segmentation은 noise cleanup과 noise cleanup을 하지 않은 segmentation이다.
이를 DSI, DSII, DSIII & DSIV라고 부르며 모델은 각자 분리하여 훈련된다.
Noise 제거
background noise를 제거하기 위해서 1Hz ~ 30KHz 사이에서 bandpass filter를 사용한다.
( bandpass filter란 특정 주파수를 걸러내주는 필터를 의미하며 1Hz~ 30KHz까지의 소리만 받아오고 그 이하 혹은 이상의 사람이 듣기 힘든 주파수는 제거해줌으로써 noise를 제거했다 생각하면 된다. )
밑에서는 초기 실험 방법과 이후 적용한 방법들에 대한 설명이다.
0. 초기에는 이를 위해 3초 길이로 0 padding을 하고, 그 후에 신호와 singal to noise ratio(SNR)가 1로 유지되는 노이즈를 신호에 추가했었지만, 이는 원래의 오디오 신호를 왜곡시키는 결과를 가져왔다.
1. 다른 실험 방법으로써 3초 이하의 짧은 문장 발화는 다른 신호의 노이즈와 노이즈 주파수 및 노이즈 크기에 대해 균일성을 유지하기 위해 노이즈를 추가하여 다른 긴 문장과 동일한 노이즈 수준으로 유지한다.
2. 그리고 그 신호를 denoising하게 되는데, denoising은 emoition에 대한 더 좋은 prediction accuracy를 가져다줄 수 있는 input audio signal의 frequency, time scale, amplitude feature를 생성하는데 도움을 준다. (특성 강화)
3. 모든 오디오 spectrogram은 다른 감정들간의 스펙트로그램 표현에서 일관성(uniformity)을 유지하기 위해 같은 colorbar intensity scale (+/- 60dB)를 사용하여 생성된다.
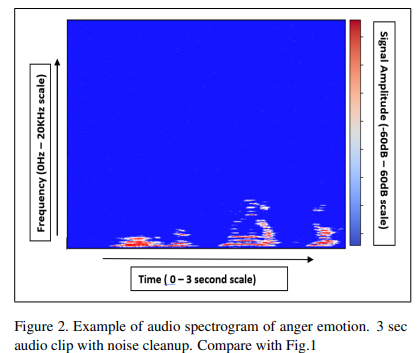
4. Fig2를 보면 denoising을 한 후 실질적인 정보를 갖고 있는 singal만 높은 power intensity(signal amplitude)를 남아 있는걸 알 수 있다. 이는 감정 예측에 중요하게 작용하게 된다.
이 과정들은 신호 처리를 통한 감정 예측에 유용한 특성을 강화하는데 사용되는 방법이다.
(노이즈를 추가하고 제거하는 방법에 대해 추후 좀 더 공부를 진행해야 할 것 같다.)
--> https://honeyjamtech.tistory.com/5 참고해서 velog정리하자.
spectrogram에서 다른 다른 부분들은 실질적인 signal에 비해 low power intenstiy를 유지한다.
위의 Fig 1과 비교해보면 time scale에 따른 특정 signal intensity를 알 수 있고, spectrogram은 200 x 300 pixel의 크기로 생성된다.
Data Augmentation & Reducing
4가지 감정에대한 3초동안의 audio spectrograms에 대한 전체 개수는 Table2와 같다.
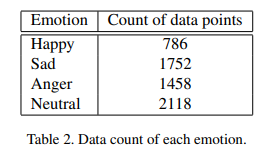
보면 Happy가 유별나게 적은데 이를 총 1600개 까지 데이터를 복제해줄 것이다.
유사하게 anger emotion 또한 데이터를 복제해서 더 생성해주고, Sad & Neutral data는 1600개에 맞춰 줄여줄 것이다.
그렇게 총 6400개의 model의 training을 위한 데이터 셋을 만들어준다. train에 있어 data balance는 굉장히 중요하며 400개는 validation purpose 나머지는 training 데이터로 쓰며, validation set에 있는 image는 절대 train set에 포함시키지 않는다.
요약
모든 데이터를 1600개에 맞춰 create & reduce
validtion: 400
training: 1200
0. 처음에는 xy축과 colobar 그대로 audio spectrogram을 가지고 진행했으나, accuracy에 부정적인 영향이 있는 것을 확인 후 axis와 scale을 제거했다.
1. class accuracy가 개선되는 것을 보기 위해, input audio spectrograms에 대해 cropping과 rotation을 통해 data augment했다.
※ cropping: 사진의 일부를 잘라내는 것
cropping
각각의 spectrogram image들은 위에서부터 10px 정도 crop하고 다시 200 x 300 pixel (원본 이미지)로 복원시킨다.
-> 아주 약간의 frequency change를 한다.
rotation
유사하게 rotation 역시 +/- 10도 정도의 아주 약간의 변화를 주며 똑같이 frequency change를 하게되며 아주 약간의 time scale의 변화 또한 생기게 된다.
-> Augmentation을 할 때 time scale을 변화하는 것은 좋지 않기 때문에 아주 작은 각도인 10도 정도만 돌린다.
그렇게 cropping하고 rotation함으로써 총 training을 위한 데이터는 19200개까지 만든다.
모델 training은 비교를 위해 원본의 이미지와 augment된 이미지가 각각 개별적으로 훈련된다.
주의할 점으론 horizontal flip(좌우반전)은 time scale을 역으로 만들며 발화를 역으로 표현하는 것과 마찬가지이기 때문에 하면 안된다.
또한 3초에 대한 것 외에 full time length를 포함하는 audio spectrogram에 대한 모델이 따로 training된다.
주어졌던 3초 audio spectrogram은 full time length spectrogram으로 대체되며 데이터수가 balance를 맞출수 있게 된다(?)
(이 부분이 이해가 안감)
100개의 audio spectrograms에 대한 visual 분석을 했을 때, maximum frequency가 8KHz 주변에 있는 것을 확인했다.
이는 spectrogram 이미지의 약 60%가 blue, 즉 어떤 emotion정보를 갖지 않는 무의미한 데이터라는 뜻을 의미힌다.
모든 input audio spectrogram에 대해 top에서부터 60%를 crop하고 200 x 300 pixel로 resize한다.
참고로 가장 이상적인 방법은 frequency range가 알려져 있다면 고정된 frequency를 가진 spectrograms을 생성하는 것이다.
3.2.2 Video Data Pre-processing
0. 비디오 데이터를 처리하기위해 우선적으로 우리가 처리한 audio file에 따라 문장 단위로 각각의 video file을 clip한다.
(Audio spectrogram에 맞는 video part에 대한 query를 만들어주게 하기 위함)
1. 그리고 20개의 3초간의 이미지를 video avi file에서 3초 오디오 spectrogram에 맞춰서 extract한다.
2. video는 emotion이 기록된 actor만을 capture하기 위해 화면의 왼쪽이나 오른쪽에서 frame을 자른다.
3. 그리고 다시 한번 더 actor의 face/head를 포함하며 다른 부분들을 더 자른다.
4. 최종적으로 video frame의 크기는 60 x 100이 된다.
데이터 셋의 한가지 제약 사항으로 모든 배우들이 카메라를 정면을 보고 있지 않기 때문에, 전체적인 얼굴 표현에 일치하는 emotion은 완전하게 보이지는 않는다.
전체적인 메모리가 12GB정도 되기 때문에 각각의 audio와 video file들은 batch에서 개별적으로 진행된다.
4. Methods & Model Architecture
4.1 Audio Models
총 3가지의 모델을 사용
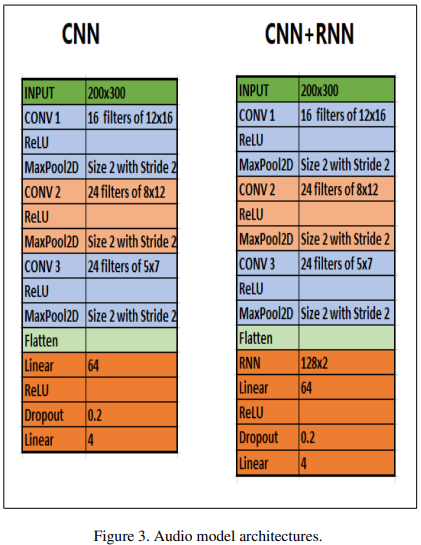
1. CNN model
3개의 2D convolutional layer와 maxpooling layer (2 fully connected layer)
2. LSTM layer 추가
CNN layer에 LSTM을 추가
3. CNN + RNN
LSTM레이어를 vanila RNN 모델로 변경
loss는 전체적으로 cross entropy를 사용함
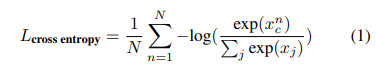
N: number of data in the dataset
xnc: true class's score of the n-th data point
xj: j-th class's score of the n-th input data
cross entropy loss를 줄이는 것은 모델이 audio spectrogram에서 감정과 관련한 features를 배우는 것을 강제할 것이다.
loss는 데이터 포인트에 대해 true class의 점수가 다른 클래스의 점수들에 비교해서 현저하게 클 경우에만 최소가되기 때문이다.
4.2 Audio + Video Models
Audio + Video Model은 2 sub-network를 포함하는 2-stream network로 이루어진다.
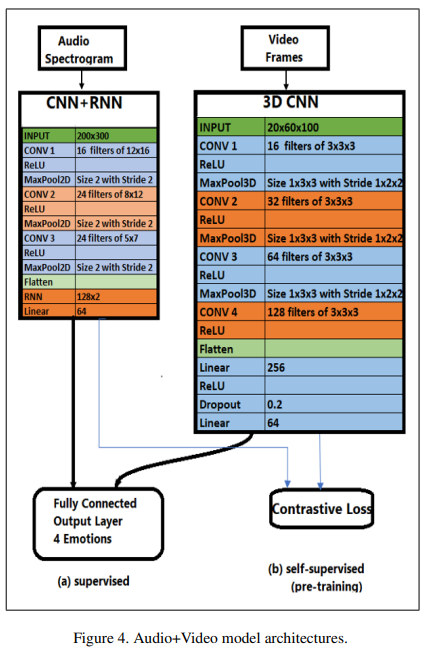
Learning 2-Methods Audio + Video Model
(a) Supervised
First sub-network: audio model
best-performing audio model을 선택하기 위해 CNN + RNN 모델을 구축했었다.
첫 번째 sub-network의 아키텍처는 audio spectrograms의 high-level features를 얻기 위해 original output layer를 dump하는 것을 제외한 오디오 모델과 같다. (CNN+RNN)
Second sub-network: video model
4개의 3D convolution layer와 3개의 3D maxpooling layer를 2개의 fully connected layer로 감싸서 진행한다.
finally, the last layer of the 2 sub-network는 하나의 output layer로 concat 된다.
(b) Semi-supervised
우선 같은 비디오에서 얻은 video fraems & audio spectrograms과 다른 비디오들에서 얻은 video fraems & audio spectrograms 모델을 pre-training한다.
-> 모델이 videos의 visual과 auditive elements의 상관성을 학습하게 한다.
5. Experiments & Results
6. Conclusion/Future Work
Reference
[1] D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper,
B. Catanzaro, J. Chen, M. Chrzanowski, A. Coates, G. Diamos, E. Elsen, J. H. Engel, L. Fan, C. Fougner, T. Han,
A. Y. Hannun, B. Jun, P. LeGresley, L. Lin, S. Narang, A. Y.
Ng, S. Ozair, R. Prenger, J. Raiman, S. Satheesh, D. Seetapun, S. Sengupta, Y. Wang, Z. Wang, C. Wang, B. Xiao,
D. Yogatama, J. Zhan, and Z. Zhu. Deep speech 2: Endto-end speech recognition in english and mandarin. CoRR,
abs/1512.02595, 2015.
[2] C. L. A. K. E. M. S. K. J. C. S. L. C. Busso, M. Bulut and S. Narayanan. Iemocap: Interactive emotional dyadic motion
capture database, December 2008.
[3] L. Deng. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Transactions on Signal and Information Processing, 3:e2, 2014.
[4] K. Gouta and M. Miyamoto. Emotion recognition: facial components associated with various emotions. Shinrigaku
kenkyu: The Japanese journal of psychology, 71(3):211–218, 2000.
[5] A. Y. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates,
and A. Y. Ng. Deep speech: Scaling up end-to-end speech recognition, 2014.
[6] W. Hashim Abdulsalam, d. al hamdani, and M. Al Salam
Facial emotion recognition from videos using deep convolutional neural networks. 9:14–19, 01 2019.
[7] J. Kim and E. Andre. Emotion recognition based on physio- ´ logical changes in music listening. IEEE transactions on pattern analysis and machine intelligence, 30(12):2067–2083,
2008.
[8] B. Korbar, D. Tran, and L. Torresani. Co-training of audio and video representations from self-supervised temporal
synchronization. CoRR, abs/1807.00230, 2018.
[9] O.-W. Kwon, K. Chan, J. Hao, and T.-W. Lee. Emotion
recognition by speech signals. In Eighth European Conference on Speech Communication and Technology, 2003.
[10] J. Lee and I. Tashev. High-level feature representation using recurrent neural network for speech emotion recognition,
September 2015.
[11] S. Minaee and A. Abdolrashidi. Deep-emotion: Facial
expression recognition using attentional convolutional network. CoRR, abs/1902.01019, 2019.
[12] G. Sahu. Multimodal speech emotion recognition and ambiguity resolution. CoRR, abs/1904.06022, 2019.
[13] A. Satt, S. Rozenberg, and R. Hoory. Efficient emotion
recognition from speech using deep learning on spectrograms, 08 2017.
[14] A. Torfi, S. M. Iranmanesh, N. M. Nasrabadi, and J. M. Dawson. Coupled 3d convolutional neural networks for aud

